从长文本智能提取知识图谱
6/19/25About 3 min
从长文本智能提取知识图谱
本文介绍如何利用大语言模型(LLM)和图数据库,从本地长文本中自动化提取知识图谱的完整流程,包括文本预处理、智能切分、三元组抽取、入库及可视化等关键步骤。
1. 读取本地长文本文件
- 支持多种文本格式(如txt、markdown、pdf、doc等),建议统一转换为markdown或txt格式,便于后续处理。
- 需注意文件编码问题,推荐使用UTF-8编码,避免乱码。
- 可参考前文关于pdf/doc转markdown的实现方法。
- 对于非文本内容(如图片、表格等),建议过滤或单独处理。

2. 智能分割长文本
- 支持多种分割策略:按固定长度、按句子结束符(如句号、问号等)等。
- 为保证上下文连贯性,建议分段时设置一定的重叠区域,避免信息割裂。
- 中文分词可采用jieba分词,英文可选用nltk、spaCy等工具。
- 对于图片或非纯文本数据,可选择跳过或单独标记,不参与知识抽取。
3. 使用LLM提取三元组(节点和关系)
- 设计合理的Prompt,明确要求输出三元组(主体-关系-客体)格式。
- 建议输出为标准JSON格式,便于后续解析与入库。
- 可尝试不同的LLM模型(如llama3.3:70b、mistral-small:latest等),对比效果。
- 对于抽取结果,建议增加后处理环节,如去重、规范化实体名称等。
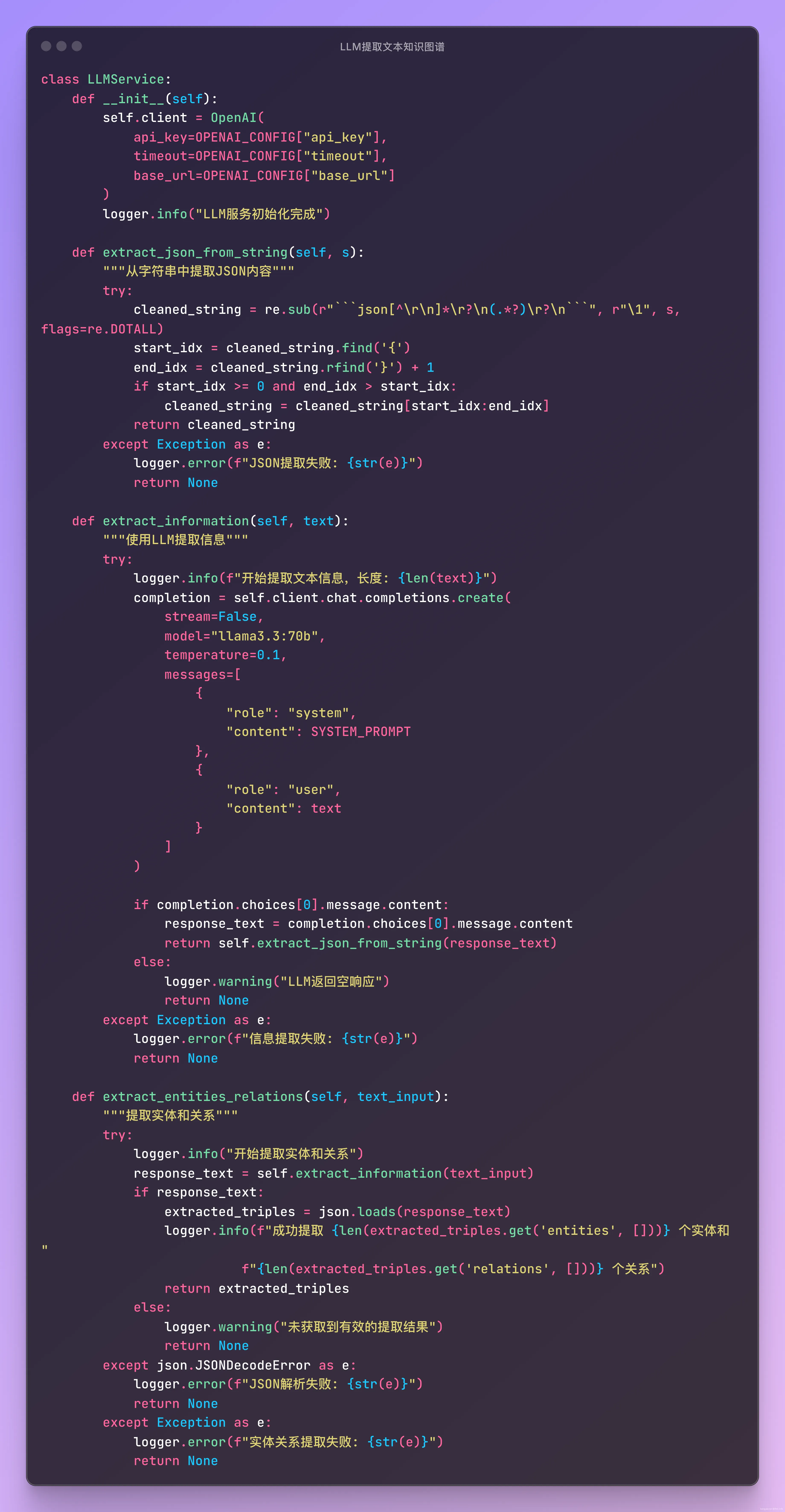
4. 保存三元组入库(neo4j)
- 解析LLM输出的三元组数据,分别创建节点和关系。
- 推荐使用py2neo、neo4j-driver等Python库进行数据库操作。
- 可根据实际需求,设计节点和关系的属性结构,支持后续查询与可视化。
5. 可视化与效果演示
- 利用neo4j自带的可视化工具或第三方前端框架,展示知识图谱结构。
- 可结合实际案例,展示从原始文本到知识图谱的完整流程和效果。
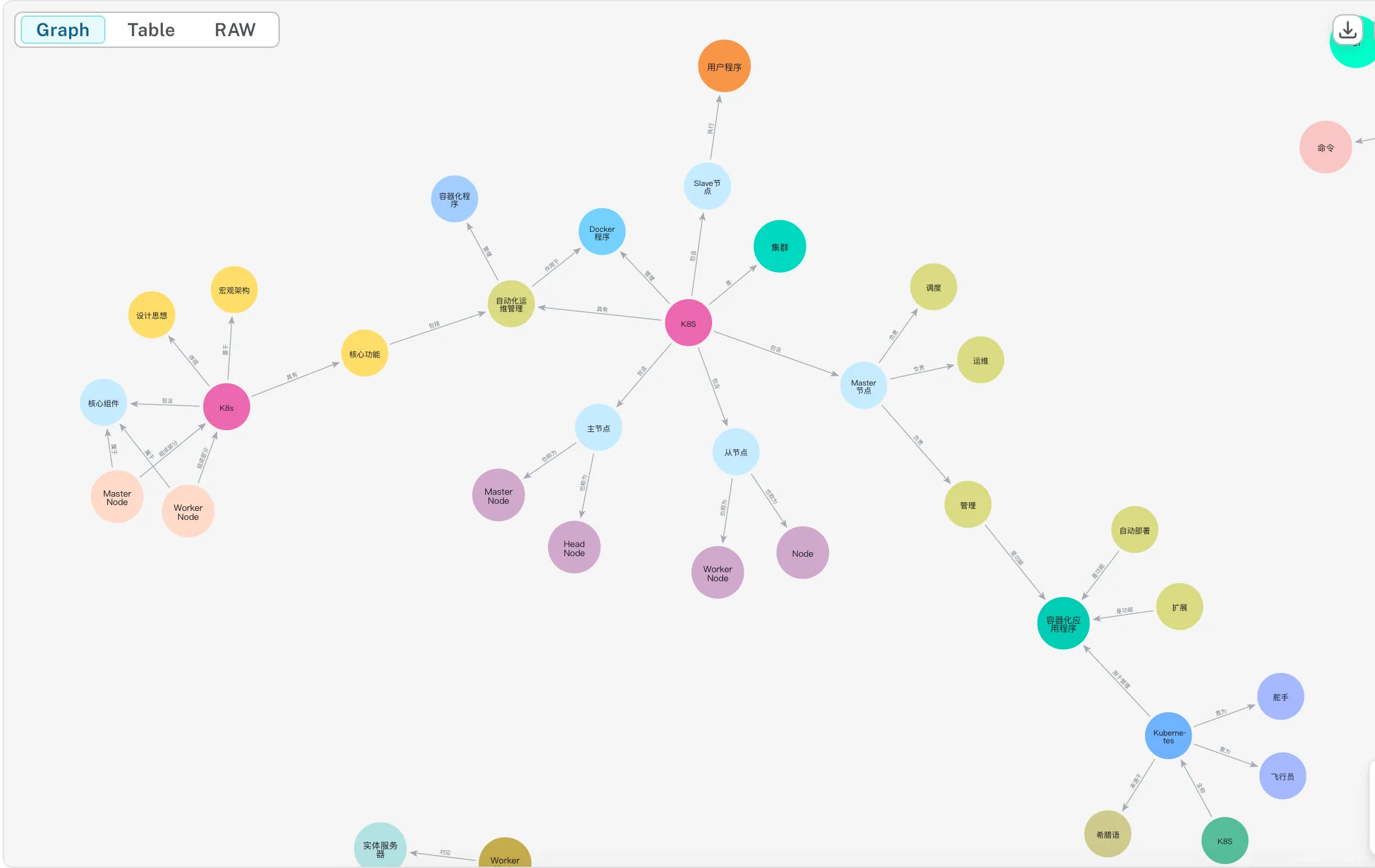
总结与建议
- 本流程适用于学术论文、技术文档、新闻报道等多种长文本场景。
- 实际应用中可根据文本类型和业务需求,灵活调整分割、抽取和入库策略。
- 推荐持续优化Prompt和后处理规则,以提升知识图谱的准确性和实用性。