RAG如何工作
6/18/25...About 5 min
RAG(Retrieval-Augmented Generation,检索增强生成)系统通过将大型语言模型(LLM)的生成能力与外部知识库的检索能力相结合,旨在提供更准确、更具时效性的回答,并有效缓解LLM可能出现的“幻觉”问题。
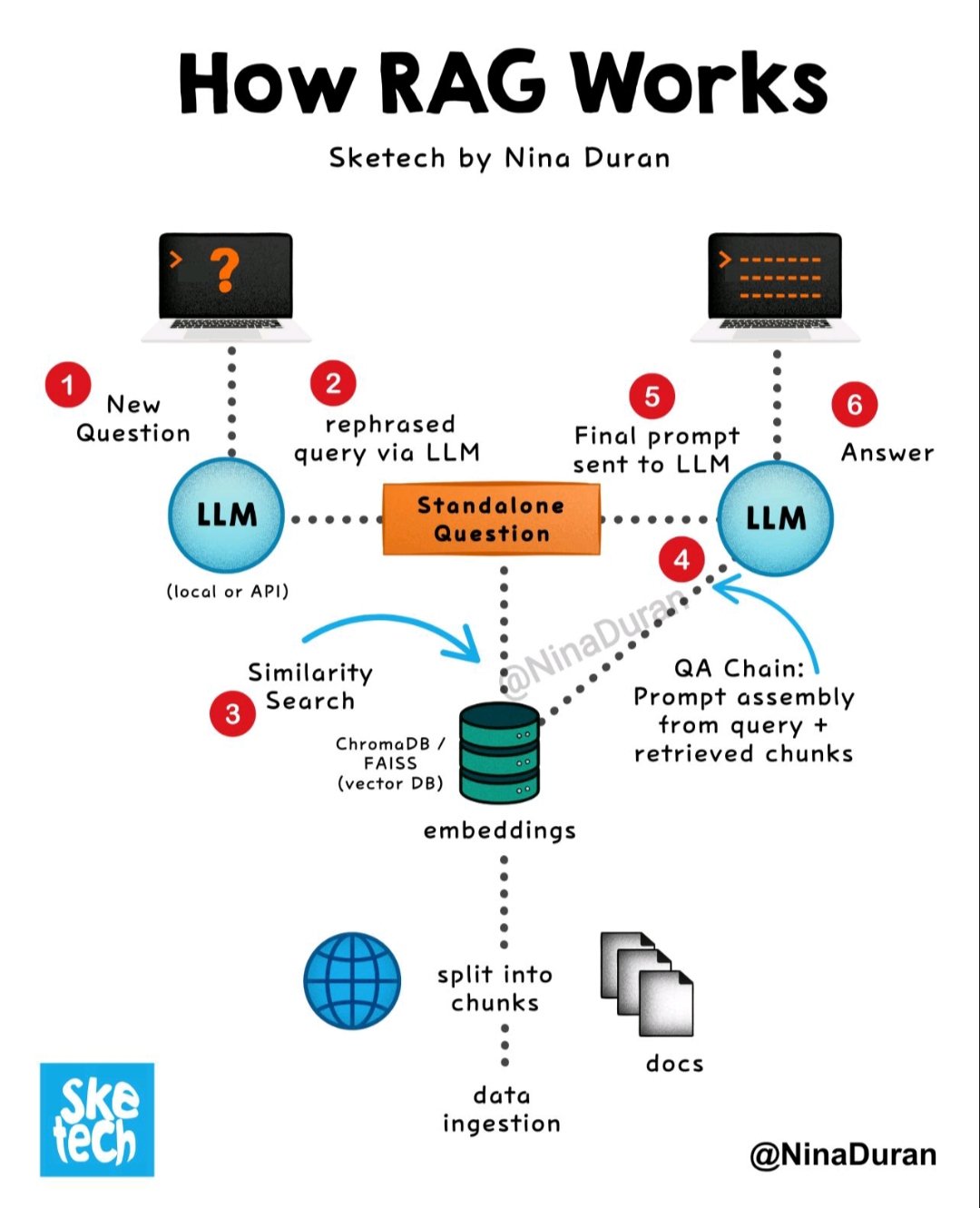
一个典型的 RAG 系统主要包含以下几个核心模块,其工作流程紧密围绕您提到的关键步骤展开:
1. 知识库准备(Data Ingestion / Indexing)
此模块的核心目标是构建一个可供高效检索的外部知识库。它涵盖了将原始数据转化为可检索向量的全过程。
1.1 划分知识库(Divide the knowledge base):
- 步骤: 将原始的文档语料库(例如:公司内部文档、网页、书籍、报告等)分解成更小、更易于管理和理解的文本片段,即“块”(chunks)。
- 目的: 大型文档通常包含的信息量巨大,直接处理会超出LLM的输入限制,且可能包含大量与查询无关的信息。分块有助于聚焦相关信息,提高检索效率和生成质量。分块策略可以多样化,如按段落、按句子、固定字数或语义相关性分块。
1.2 创建嵌入(Create embeddings):
- 步骤: 对每个文本块应用一个嵌入模型(Embedding Model),将其转换为高维的数值向量(embeddings)。
- 目的: 嵌入向量能够捕捉文本的语义含义,使得语义上相似的文本块在向量空间中彼此靠近。这是后续向量相似度搜索的基础。
1.3 存储在向量数据库(Store in a vector database):
- 步骤: 将生成的文本块嵌入(向量)与原始文本块的引用信息(如ID、原始文本)一起存储在专门优化的**向量数据库(Vector Database)**中。
- 目的: 向量数据库能够高效地执行向量相似度搜索,快速找出与查询向量最相似的文本块。
2. 检索器 (Retriever)
检索器的任务是根据用户的查询,从预处理好的知识库中高效地找出最相关的文本块。
2.1 处理用户查询(Handle user queries):
- 步骤: 当用户输入一个问题或查询时,使用与知识库构建时相同的嵌入模型,将用户查询也转换为一个高维向量。
- 目的: 确保用户查询和知识库中的文本块处于相同的向量空间,以便进行有效的相似度比较。
2.2 检索相关数据(Retrieve relevant data):
- 步骤: 在向量数据库中执行向量相似度搜索,根据用户查询向量与存储的文本块向量之间的语义相似性(例如余弦相似度),找出最匹配的K个(Top-K)文本块。
- 目的: 找到与用户查询语义最接近的知识片段,为后续的生成提供高质量的背景信息。
- (可选)重排序 (Reranker): 在一些高级实现中,检索到的初步结果会通过一个独立的重排序模型进行二次评估和排序,以进一步优化相关性,去除噪声,确保送给LLM的上下文是最精确的。
3. 生成器 (Generator)
生成器是RAG系统中的大型语言模型(LLM),负责整合检索到的信息和原始查询,生成最终的回答。
3.1 增强提示(Enhance the prompt):
- 步骤: 将检索器找到的K个最相关的文本块,作为额外的上下文信息,巧妙地整合到原始的用户查询中,形成一个增强的提示(augmented prompt)。
- 示例结构: "请回答以下问题:[用户查询] 。请参考以下信息进行回答:[检索到的相关文本块1]\n[检索到的相关文本块2]\n..."
- 目的: 为LLM提供必要的外部知识和事实依据,使其在生成回答时有“据”可循,避免“幻觉”,并能给出更具体、更准确的回答。
3.2 生成响应(Generate a response):
- 步骤: 将这个增强的提示输入到大型语言模型中。LLM结合其自身强大的语言理解和生成能力,以及提示中提供的具体上下文信息,生成一个连贯、准确且与用户查询高度相关的最终回答。
- 目的: 利用LLM的强大能力,将检索到的碎片化信息整合为自然语言的回答,并确保信息的准确性、完整性和连贯性。
总结流程图:
- 离线阶段(知识库构建):
- 原始文档 -> 划分知识库 -> 创建嵌入 -> 存储在向量数据库
- 在线阶段(查询与生成):
- 用户查询 -> 处理用户查询 (向量化) -> 检索相关数据 (向量相似度搜索) -> 增强提示 (合并查询与检索结果) -> 生成响应 (LLM根据增强提示生成)
通过以上步骤,RAG 系统有效地弥补了传统 LLM 在处理实时、领域特定或私有知识方面的不足,显著提升了其回答的准确性和可靠性。