神经网络正在如何革新3D渲染技术?
神经网络正在如何革新3D渲染技术?
你有没有想过,3D 游戏或电影中那些光影流转、极度逼真的画面到底是怎么做出来的?这背后最核心的技术就是——渲染。也就是让电脑根据3D模型,计算光的传播、反射与折射,最终生成一张二维图像。
但这个过程可不是轻松的,因为:光太复杂了。
光的复杂性:为什么“全局光照”是个大难题?
举个简单的例子。想象一个阳光洒进房间的场景,房间里放着一个红苹果:
直接光照: 太阳光照在苹果上,这是最直接的部分。
全局光照(Global Illumination): 更难的部分来了:
- 光从地板反射到苹果底部;
- 光从苹果反弹到白墙,墙面泛出淡淡的红;
- 整个房间都因光的反弹而亮起来,而不是只有一块光斑。
这种光在场景中“反弹多次”的过程,才是让画面真实的关键。但同时,它也让渲染计算变得极度复杂和耗时。传统的光线追踪技术虽然精准,但有时一张图可能要渲染几个小时!
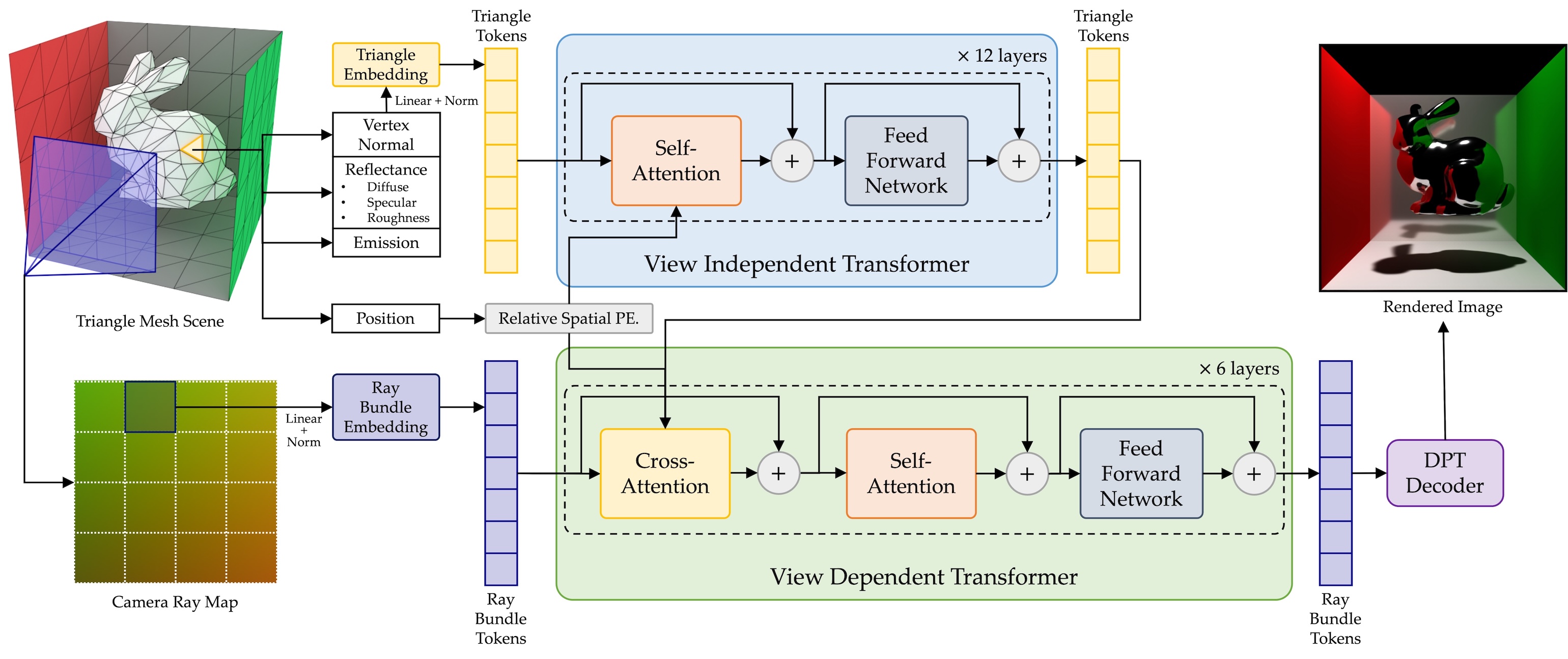
RenderFormer:来自微软的新一代“神经渲染架构”
为了解决这个问题,微软研究团队提出了一个创新的方法:RenderFormer。它将人工智能中最强大的模型之一——Transformer,引入到了3D渲染的领域。
核心理念是:
用 神经网络 学会光照是怎么传播的,跳过复杂计算,直接预测最终图像。
RenderFormer 怎么运作的?
RenderFormer 的工作流程可以简单分为三步:
1. 表达整个3D场景:用三角形表示一切
- 每个物体表面都被表示为一个个三角形(称为 Triangle Token),每个三角形都携带它的位置、法线、材质信息(如漫反射色、粗糙度、金属度等)。
- 光源也被表达为带有“自发光属性”的三角形。
2. 输入视角信息:用射线束描述相机视角
- 对于每个要渲染的画面(比如一张2D图像),系统将其划分为矩形小块,每块用一个 Ray Bundle Token(视线束) 表示。
- 每个射线束代表从相机出发,穿过画面的一组光线,指向3D空间。
3. Transformer 开始渲染预测
- 所有这些 Triangle Token 和 Ray Bundle Token 进入一个基于 Transformer 架构 的神经网络。
- Transformer 拥有强大的全局建模能力,可以同时“看到”整个场景,并理解光线和物体之间的关系。
- 最终,它输出一组图像像素的特征(对应每个视角输入),这些特征被解码生成最终渲染图像。
为什么 Transformer 在这里大放异彩?
Transformer 原本是为自然语言处理设计的,比如聊天机器人或翻译系统。但它也有一个强项:处理“序列到序列”的问题。
在 RenderFormer 中:
- 输入序列: 整个场景和光照信息(Triangle Tokens + Ray Bundles)
- 输出序列: 每个像素对应的渲染结果
Transformer 能很好地捕捉整个场景中“谁影响谁”的关系,比如:
“这道光从窗户进来,打到地板上,再反射到椅子,然后再影响摄像头看到的那个像素。”
它不需要像传统算法那样一条一条光线去追踪,而是通过学习大规模数据中的光照分布规律,直接预测最合理的渲染结果。
技术亮点
- ⚙️ 基于 Transformer 的架构: 让模型具备全球视角和多步推理能力。
- 🌍 模拟全局光照: 能精准模拟多次光反射,生成更真实的图像。
- 🧠 神经渲染方法: 直接用神经网络预测图像,不走传统渲染路径。
总结一下
RenderFormer 的关键突破是:
它把原本在自然语言处理大显身手的 Transformer,迁移到复杂的图形学场景中,解决了传统渲染计算效率低的问题。
就像一位有丰富经验的画家,只要看一眼房间的结构和光源,就能画出光影真实的画面,而不需要每条光线都计算。
对于游戏、影视、VR/AR 等对图像质量要求极高的行业来说,这是一项令人兴奋的革新。未来的虚拟世界,会变得更加真实、更加高效。
📄 论文链接
RenderFormer: Neural Scene Rendering with Ray-Bundle Transformers (arXiv)
💻 项目主页 & 代码
https://microsoft.github.io/renderformer/