Extracting Knowledge Graphs from Long Texts with AI
7/30/25...About 2 min
Extracting Knowledge Graphs from Long Texts with AI
This article introduces a complete process for automatically extracting knowledge graphs from local long texts using large language models (LLMs) and graph databases, including text preprocessing, intelligent segmentation, triple extraction, database storage, and visualization.
1. Reading Local Long Text Files
- Supports multiple text formats (such as txt, markdown, pdf, doc, etc.), it is recommended to convert them uniformly to markdown or txt format for subsequent processing.
- Pay attention to file encoding issues, it is recommended to use UTF-8 encoding to avoid garbled text.
- Refer to previous articles for methods to convert pdf/doc to markdown.
- For non-text content (such as images, tables, etc.), it is recommended to filter or handle them separately.

2. Intelligent Segmentation of Long Texts
- Supports multiple segmentation strategies: by fixed length, by sentence-ending punctuation (such as period, question mark, etc.), etc.
- To ensure contextual coherence, it is recommended to set a certain overlap area when segmenting to avoid information loss.
- For Chinese word segmentation, you can use jieba; for English, you can use nltk, spaCy, etc.
- For images or non-pure text data, you can choose to skip or mark them separately, not participating in knowledge extraction.
3. Using LLM to Extract Triples (Entities and Relations)
- Design reasonable Prompts to clearly require output in triple (subject-relation-object) format.
- It is recommended to output in standard JSON format for subsequent analysis and database storage.
- Try different LLM models (such as llama3.3:70b, mistral-small:latest, etc.) to compare results.
- For extraction results, it is recommended to add post-processing steps, such as deduplication and normalization of entity names.
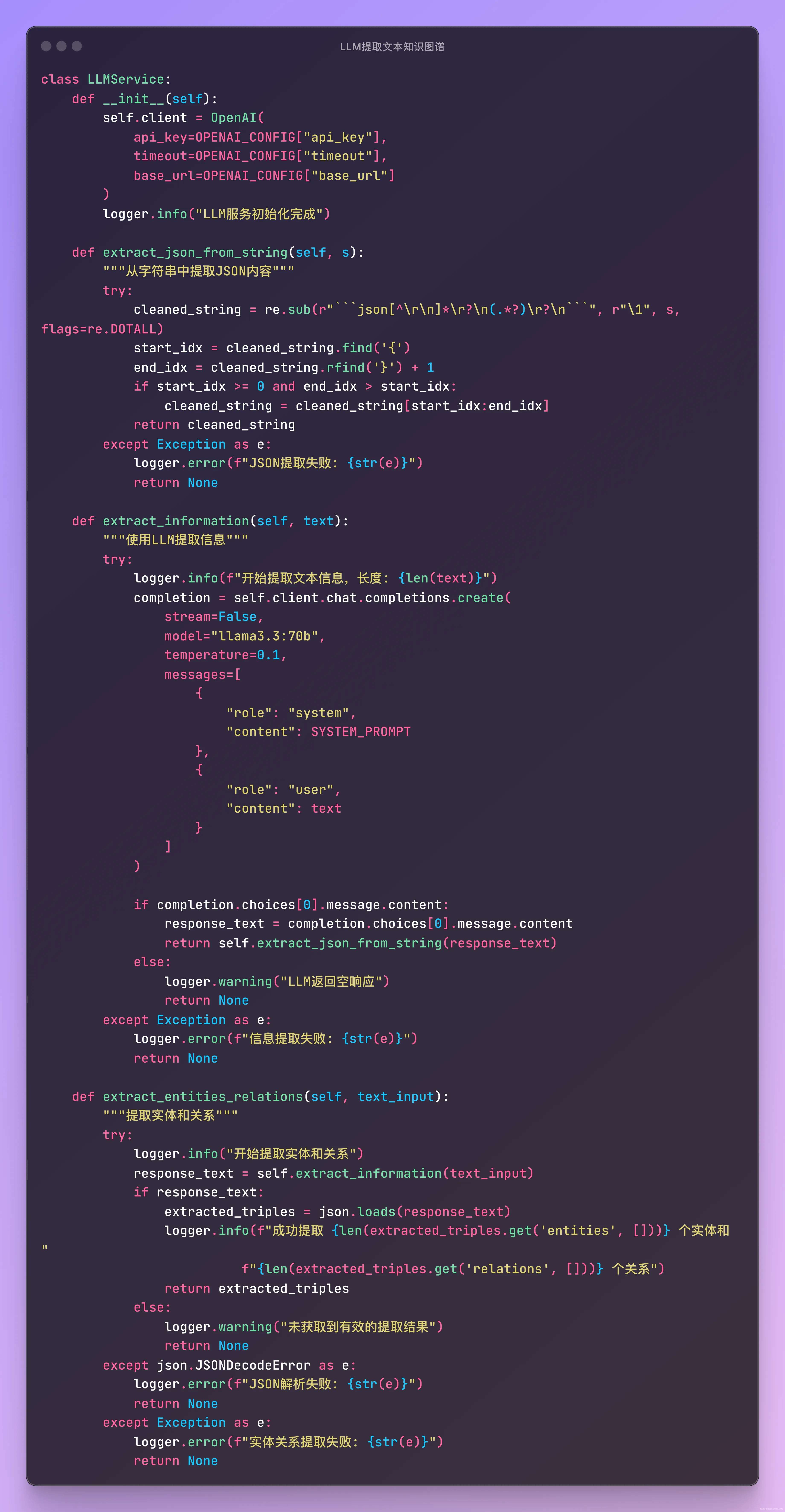
4. Save Triples to Database (neo4j)
- Parse the triple data output by LLM, and create nodes and relationships respectively.
- It is recommended to use Python libraries such as py2neo and neo4j-driver for database operations.
- According to actual needs, design the attribute structure of nodes and relationships to support subsequent queries and visualization.
5. Visualization and Effect Demonstration
- Use neo4j's built-in visualization tools or third-party front-end frameworks to display the structure of the knowledge graph.
- Combine with practical cases to demonstrate the complete process and effect from original text to knowledge graph.
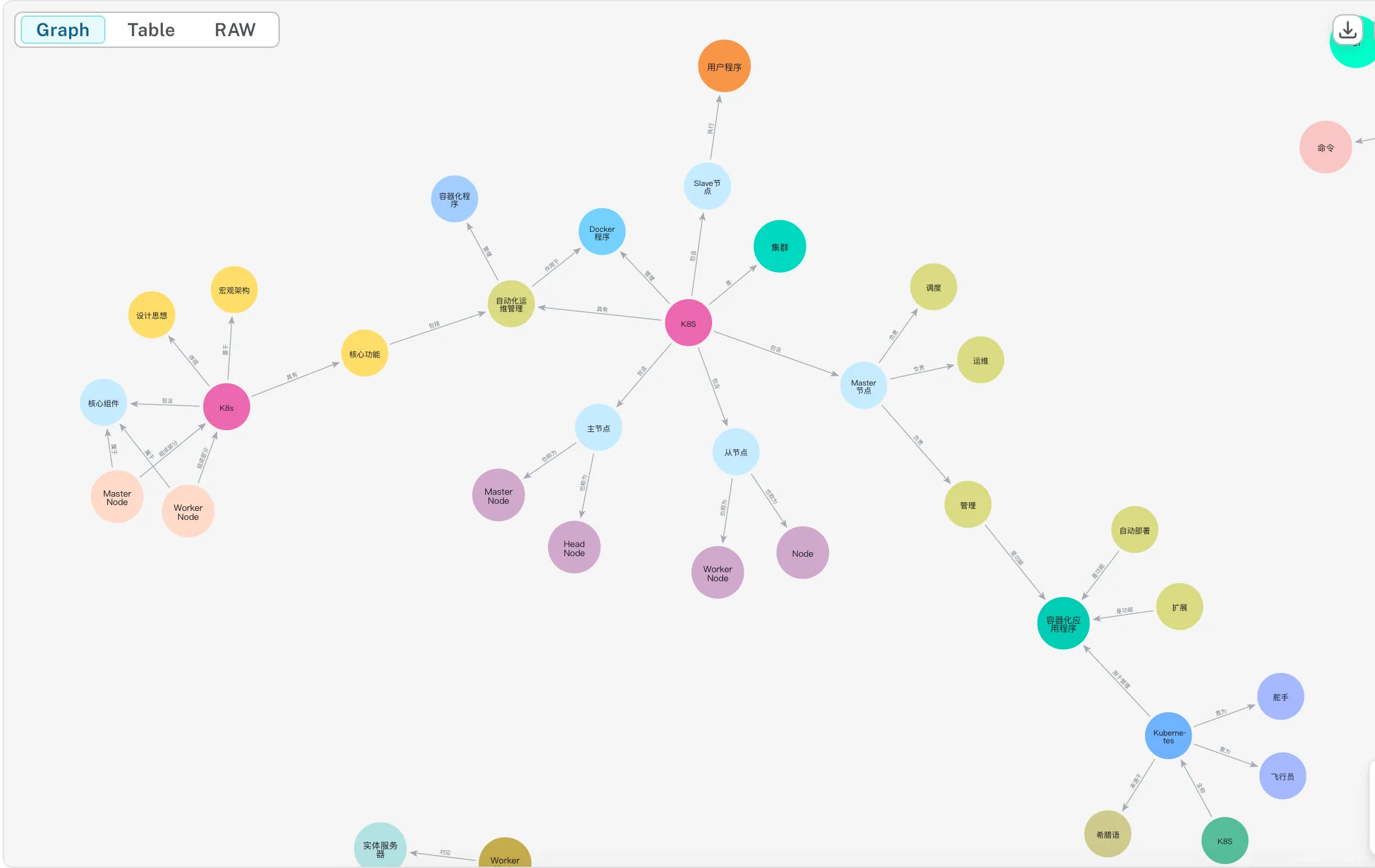
Summary and Suggestions
- This process is suitable for various long text scenarios such as academic papers, technical documents, and news reports.
- In practical applications, you can flexibly adjust segmentation, extraction, and storage strategies according to text types and business needs.
- It is recommended to continuously optimize Prompts and post-processing rules to improve the accuracy and practicality of knowledge graphs.