How RAG Works
RAG (Retrieval-Augmented Generation) systems combine the generative power of large language models (LLMs) with the retrieval capabilities of external knowledge bases to provide more accurate and timely answers, effectively mitigating the "hallucination" problem of LLMs.
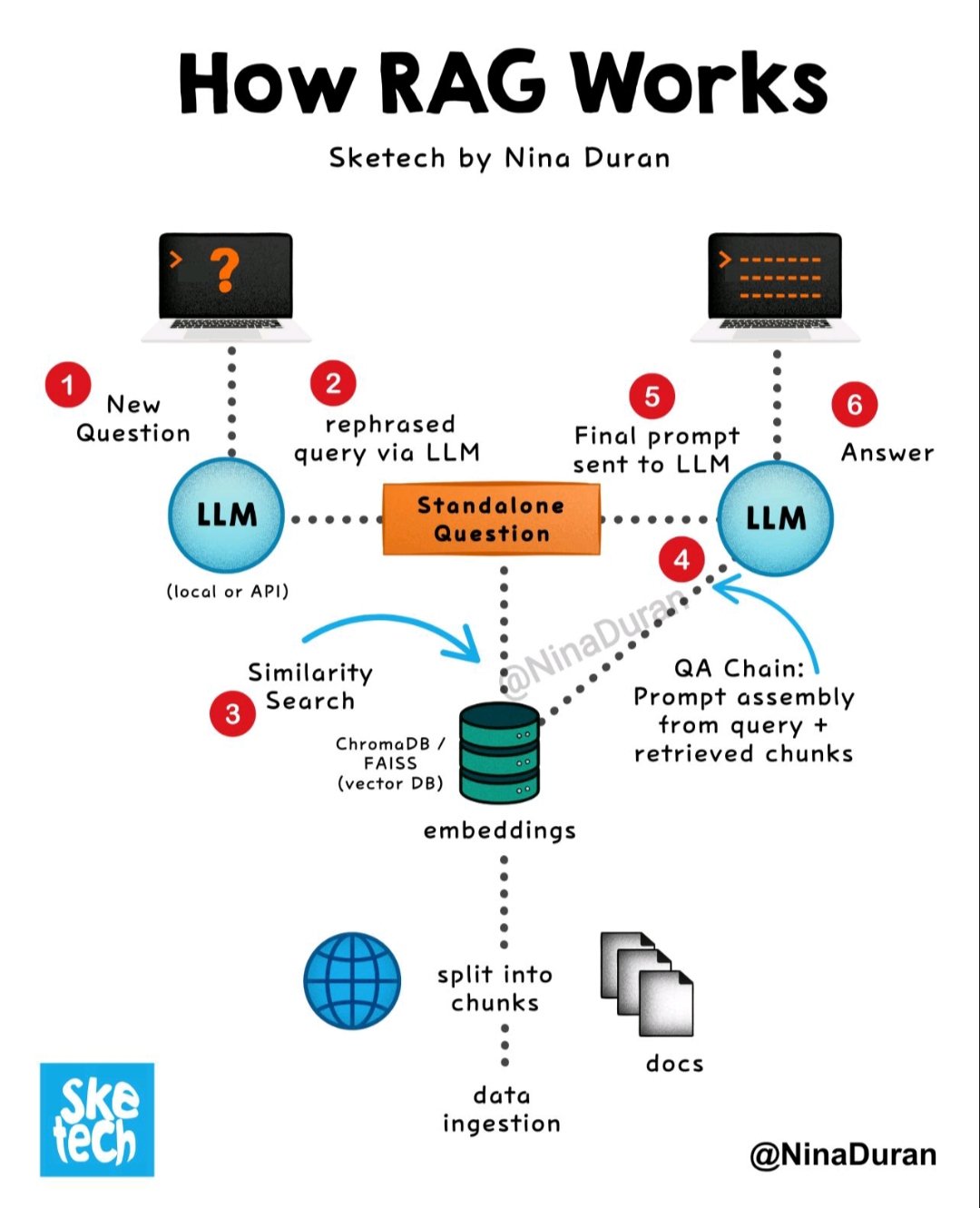
A typical RAG system mainly consists of the following core modules, with its workflow closely revolving around the key steps you mentioned:
1. Knowledge Base Preparation (Data Ingestion / Indexing)
The core goal of this module is to build an external knowledge base that can be efficiently retrieved. It covers the entire process of transforming raw data into searchable vectors.
1.1 Divide the Knowledge Base:
- Steps: Break down original document corpora (e.g., internal company docs, web pages, books, reports) into smaller, more manageable text chunks ("chunks").
- Purpose: Large documents often contain massive amounts of information, which can exceed the LLM's input limit and may include irrelevant data. Chunking helps focus on relevant information, improving retrieval efficiency and generation quality. Chunking strategies can vary, such as by paragraph, sentence, fixed word count, or semantic relevance.
1.2 Create Embeddings:
- Steps: Apply an embedding model to each text chunk, converting it into a high-dimensional numeric vector (embedding).
- Purpose: Embeddings capture the semantic meaning of text, so semantically similar chunks are close together in vector space. This is the foundation for subsequent vector similarity search.
1.3 Store in a Vector Database:
- Steps: Store the generated text chunk embeddings and their references (e.g., ID, original text) in a specialized vector database.
- Purpose: Vector databases can efficiently perform similarity searches, quickly finding the text chunks most similar to a query vector.
2. Retriever
The retriever's job is to efficiently find the most relevant text chunks from the prepared knowledge base based on the user's query.
2.1 Handle User Queries:
- Steps: When a user enters a question or query, use the same embedding model as used for the knowledge base to convert the query into a high-dimensional vector.
- Purpose: Ensures that user queries and knowledge base chunks are in the same vector space for effective similarity comparison.
2.2 Retrieve Relevant Data:
- Steps: Perform vector similarity search in the vector database, comparing the query vector with stored chunk vectors to find the top-K most similar chunks.
- Purpose: Find the knowledge fragments most semantically similar to the user's query, providing high-quality background information for generation.
- (Optional) Reranker: In advanced implementations, initial retrieval results may be re-ranked by a separate model to further optimize relevance and ensure the LLM receives the most accurate context.
3. Generator
The generator is the large language model (LLM) in the RAG system, responsible for integrating the retrieved information and the original query to generate the final answer.
3.1 Enhance the Prompt:
- Steps: Take the top-K most relevant chunks found by the retriever and integrate them as additional context into the user's original query, forming an augmented prompt.
- Example Structure: "Please answer the following question: [user query]. Please refer to the following information: [retrieved chunk 1]\n[retrieved chunk 2]\n..."
- Purpose: Provide the LLM with necessary external knowledge and factual data, so its generation is grounded in real information, avoiding hallucination and producing more specific and accurate answers.
3.2 Generate a Response:
- Steps: Input the augmented prompt into the LLM. The LLM combines its own strong language understanding and generation abilities with the specific context provided in the prompt to generate a coherent, accurate, and highly relevant final answer.
- Purpose: Leverage the LLM's power to synthesize the retrieved fragments into a natural language answer, ensuring accuracy, completeness, and coherence.
Summary Workflow Diagram:
- Offline Stage (Knowledge Base Construction):
- Original documents -> Divide Knowledge Base -> Create Embeddings -> Store in Vector Database
- Online Stage (Query & Generation):
- User query -> Handle User Query (embedding) -> Retrieve Relevant Data (vector similarity search) -> Enhance Prompt (merge query and retrieval results) -> Generate Response (LLM generates based on augmented prompt)
By following these steps, a RAG system effectively compensates for the shortcomings of traditional LLMs in handling real-time, domain-specific, or private knowledge, significantly improving the accuracy and reliability of its answers.