How Neural Networks Are Revolutionizing 3D Rendering Technology
How Neural Networks Are Revolutionizing 3D Rendering Technology
Have you ever wondered how those flowing, hyper-realistic scenes in 3D games or movies are actually made? The core technology behind them is—rendering. That is, letting the computer calculate the propagation, reflection, and refraction of light based on 3D models, and finally generate a 2D image.
But this process is not easy, because: Light is very complex.
The Complexity of Light: Why is "Global Illumination" So Hard?
A simple example. Imagine sunlight shining into a room with a red apple inside:
Direct Illumination: Sunlight shines directly on the apple—this is the most straightforward part.
Global Illumination: The harder part:
- Light reflects from the floor to the bottom of the apple;
- Light bounces from the apple to the white wall, tinting the wall with a faint red;
- The whole room is brightened by multiple bounces of light, not just a single bright spot.
This process of light "bouncing multiple times" in a scene is the key to realistic images. But it also makes rendering calculations extremely complex and time-consuming. Traditional ray tracing is accurate, but sometimes a single image can take hours to render!
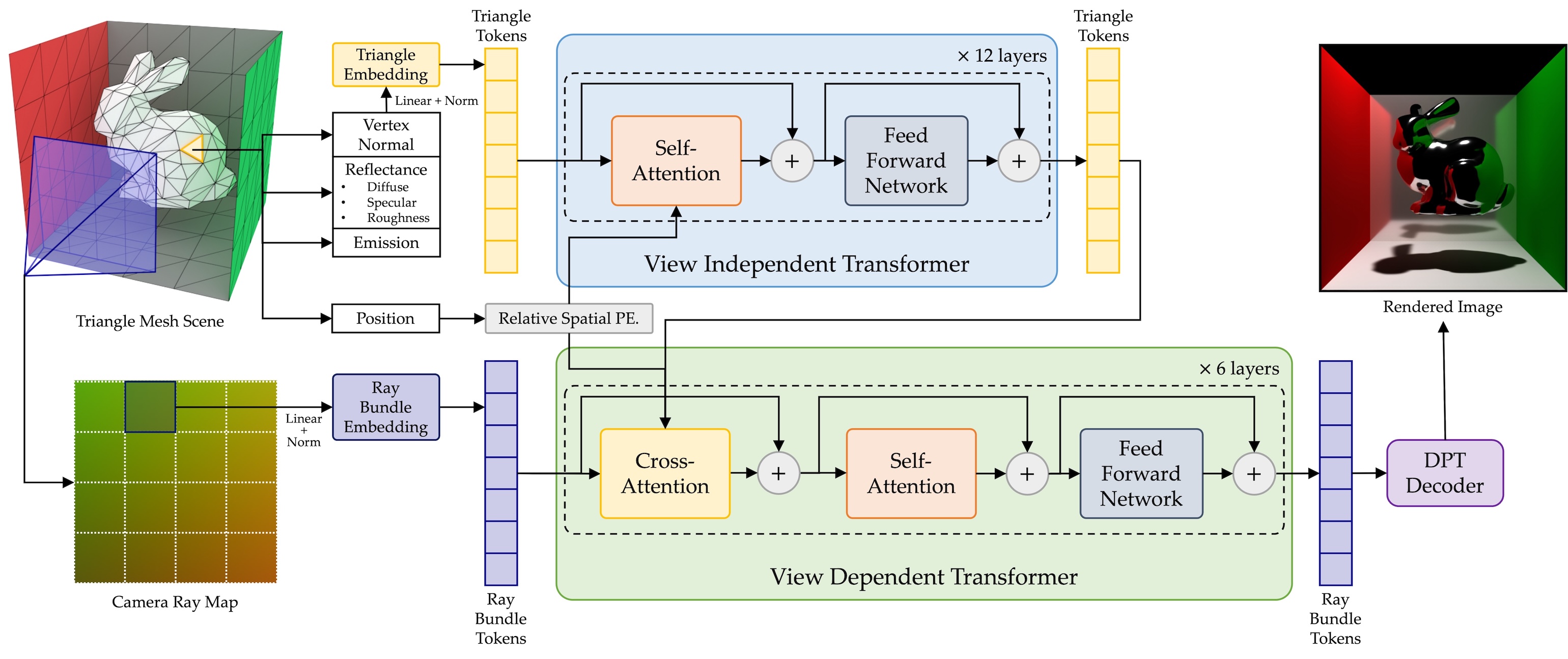
RenderFormer: Microsoft's New Generation of "Neural Rendering Architecture"
To solve this, Microsoft Research proposed an innovative method: RenderFormer. It brings one of the most powerful models in AI—Transformer—into the field of 3D rendering.
The core idea is:
Use neural networks to learn how light propagates, skipping complex calculations and directly predicting the final image.
How Does RenderFormer Work?
RenderFormer's workflow can be simply divided into three steps:
1. Represent the Entire 3D Scene: Everything as Triangles
- Every object surface is represented as a triangle (called a Triangle Token), each carrying its position, normal, and material info (like albedo, roughness, metallicity, etc.).
- Light sources are also represented as triangles with "emissive properties".
2. Input Viewpoint Info: Ray Bundles Describe Camera Views
- For each image to be rendered (e.g., a 2D image), the system divides it into rectangular patches, each represented by a Ray Bundle Token.
- Each ray bundle represents a group of rays from the camera passing through the image, pointing into 3D space.
3. Transformer Starts Rendering Prediction
- All these Triangle Tokens and Ray Bundle Tokens are fed into a Transformer-based neural network.
- The Transformer, with its powerful global modeling ability, can "see" the whole scene and understand the relationships between rays and objects.
- Finally, it outputs a set of image pixel features (corresponding to each viewpoint input), which are decoded into the final rendered image.
Why Do Transformers Shine Here?
Transformers were originally designed for natural language processing, like chatbots or translation systems. But they have a strength: handling "sequence-to-sequence" problems.
In RenderFormer:
- Input sequence: The whole scene and lighting info (Triangle Tokens + Ray Bundles)
- Output sequence: The rendered result for each pixel
Transformers can capture "who affects whom" in the scene, for example:
"This light comes in from the window, hits the floor, then bounces to the chair, and finally affects the pixel seen by the camera."
It doesn't need to trace every light ray like traditional algorithms, but learns the global lighting distribution from large-scale data and directly predicts the most reasonable rendering result.
Technical Highlights
- ⚙️ Transformer-based architecture: Gives the model global perspective and multi-step reasoning ability.
- 🌍 Simulates global illumination: Accurately models multiple light bounces for more realistic images.
- 🧠 Neural rendering method: Directly predicts images with neural networks, skipping traditional rendering paths.
In Summary
RenderFormer's key breakthrough is:
It brings the Transformer, originally dominant in natural language processing, into the complex world of graphics, solving the low efficiency of traditional rendering calculations.
Like an experienced artist who, just by looking at the structure and lighting of a room, can paint a realistic scene without calculating every light ray.
For industries like gaming, film, and VR/AR that demand extremely high image quality, this is an exciting revolution. The virtual worlds of the future will become more realistic and efficient.
📄 Paper Link
RenderFormer: Neural Scene Rendering with Ray-Bundle Transformers (arXiv)
💻 Project Homepage & Code
https://microsoft.github.io/renderformer/