一张图看懂软件架构的风格与模式
2025/10/31...大约 8 分钟
架构师的“藏宝图”:一张图看懂软件架构的风格与模式
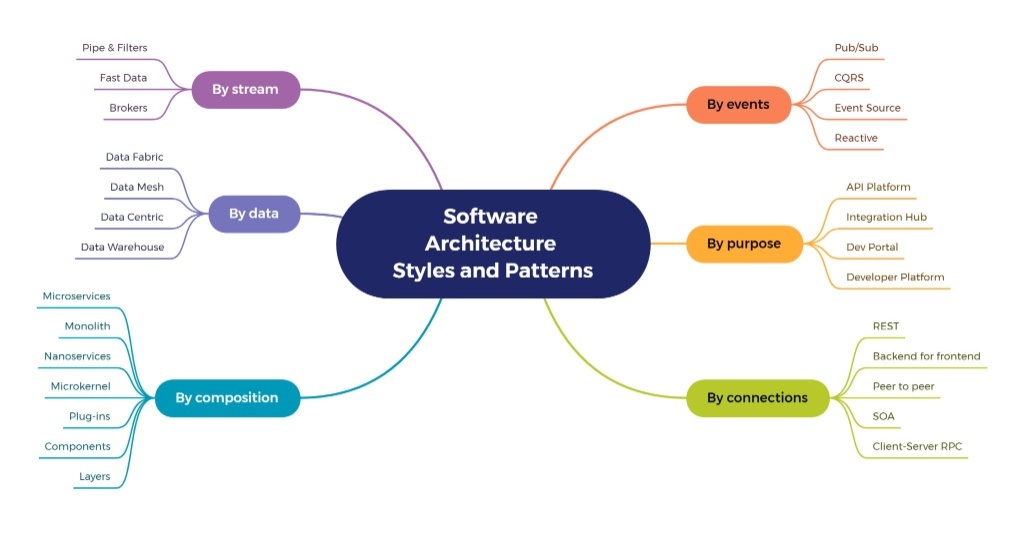
在软件工程的世界里,“架构”是我们的蓝图。它决定了系统的骨架、组件的划分以及它们之间的通信方式。一个糟糕的架构可能导致系统难以维护、扩展和理解;而一个优秀的架构,则能让团队高效协作,使系统在面对变化时依然稳健。
但“优秀”并非千篇一律。不存在能解决所有问题的“银弹”架构。相反,架构师的工具箱里装满了各种风格(Styles)和模式(Patterns),每一种都有其特定的适用场景。
今天,我们将以一张出色的思维导图(来自 TechWorld with Milan)为向导,解构这些复杂的概念。这张图巧妙地将架构分成了六大类,为我们提供了一个清晰的“藏宝图”。
1. 🏗️ 按组合 (By Composition):系统是如何“搭建”的?
这是我们最常讨论的类别,它关注的是系统的物理和逻辑结构。
- Monolith (单体架构):最传统的方式。所有功能——界面、业务逻辑、数据访问——都打包在同一个应用程序中。优点是开发简单、易于部署;缺点是随着功能增多,会变得臃肿且难以维护。
- Microservices (微服务):单体的反面。将应用拆分成一组小型的、独立部署的服务。每个服务都围绕一个业务能力构建,并通过轻量级 API(如 REST)通信。这极大地提高了可伸缩性、灵活性和团队自治能力。
- Nanoservices (纳米服务):微服务的更极端形式,服务粒度“比微服务还小”。这在实践中常被认为是一种反模式(anti-pattern),因为它可能导致过度的复杂性和网络开销。
- Layers (分层架构):经典的N层架构。将系统横向切分为表现层、业务逻辑层、数据访问层等。这是一种清晰的关注点分离,也是许多单体和面向服务架构的基础。
- Microkernel & Plug-ins (微内核与插件):又称插件化架构。系统有一个最小的核心功能(Microkernel),其他高级功能则通过“插件”的形式添加。这种架构的扩展性极强,我们熟知的 VS Code、Eclipse 甚至浏览器都是这种模式的典范。
- Components (组件化):将系统看作是可替换、可重用组件的集合。它强调的是模块化和接口定义。
2. 🔄 按连接 (By Connections):组件间如何“对话”?
如果说“组合”定义了“有什么”,那么“连接”就定义了它们“如何沟通”。
- REST (表征状态转移):当今 Web API 的事实标准。它使用标准的 HTTP 方法(GET, POST, PUT, DELETE)对资源进行操作,是无状态且易于理解的。
- Client-Server RPC (客户端-服务器远程过程调用):一种更紧密的通信方式。客户端像调用本地函数一样调用服务器上的函数(例如 gRPC)。它性能高,但耦合性也比 REST 强。
- SOA (面向服务的架构):微服务的“前身”。SOA 也提倡服务化,但它通常依赖于更“重”的协议(如 SOAP)和一个中心化的“企业服务总线”(ESB)来进行服务间的协调。
- Peer to peer (P2P):去中心化架构。网络中的每个节点(Peer)既是客户端也是服务器,它们直接相互通信,没有中心协调者。区块链和BT下载是典型的 P2P 应用。
- Backend for Frontend (BFF):一种 API 模式。它不是为所有客户端创建一个通用后端,而是为每种客户端(如 Web端、iOS端、Android端)创建一个专门的后端服务。这个 BFF 负责聚合和裁剪数据,以完美适应特定前端的需求。
3. ⚡ 按事件 (By Events):系统如何“响应”变化?
这类架构不依赖于直接的请求/响应,而是通过“事件”来驱动流程,实现高度解耦。
- Pub/Sub (发布/订阅):最基础的事件模式。服务(发布者)将事件发送到一个“主题”(Topic),而不需要知道谁在监听。其他服务(订阅者)可以订阅它们感兴趣的主题来接收事件。
- Reactive (响应式架构):这更像是一套原则。构建的系统要具备响应性、弹性、韧性和消息驱动的特点,确保在面对高并发和失败时仍能及时响应。
- Event Sourcing (事件溯源):一种根本性的转变。它不存储对象的最终状态,而是存储导致该状态的所有事件(变更历史)。系统的当前状态是通过重放这些事件计算得出的。
- CQRS (命令查询职责分离):一种将“写”操作(Command)和“读”操作(Query)分离的模式。写操作的模型专注于处理业务逻辑和验证,而读操作的模型则被高度优化以供查询。CQRS 经常与事件溯源一起使用。
4. 🌊 按流 (By Stream):如何处理“流动”的数据?
当数据不是静态的,而是以持续不断的流形式出现时,我们需要专门的架构来处理它。
- Pipe & Filters (管道与过滤器):一个经典的数据处理模式。数据流过一系列独立的“过滤器”(Filters),每个过滤器执行一项单一的转换任务,然后将结果传递给下一个(通过“管道”)。
- Brokers (代理模式):使用一个中心化的消息代理(如 Kafka, RabbitMQ)来管理数据流。生产者将数据流发送到代理,消费者从代理拉取数据流。这是实现 Pub/Sub 和流处理的核心组件。
- Fast Data (快速数据):指那些需要被立即处理的实时数据。这是一种用于低延迟、高吞吐量场景(如金融交易、物联网)的架构风格。
5. 💾 按数据 (By Data):如何组织和管理“数据”?
这类架构风格的核心是数据本身,关注如何存储、访问和治理数据资产。
- Data Warehouse (数据仓库):一个大型的、中心化的数据存储库,主要用于存储来自不同业务系统的历史结构化数据,专为商业智能(BI)和分析报表而优化。
- Data Centric (数据中心化):一种理念,将数据视为企业最核心、最持久的资产,而应用程序则是围绕这些数据构建的、可插拔的组件。
- Data Mesh (数据网格):一种现代的、去中心化的数据架构。它反对中心化的数据仓库,提倡将数据按业务领域(Domain)划分,由各领域团队将其作为“数据产品”来拥有和提供。
- Data Fabric (数据编织):可以理解为一个智能的“虚拟化”数据层。它不移动数据,而是通过元数据管理和AI技术,在多个异构数据源之上提供一个统一的数据访问和治理视图。
6. 🎯 按目的 (By Purpose):系统是用来“做什么”的?
最后,有些架构是按其在企业中的特定角色来定义的。
- API Platform / Developer Platform (API 平台 / 开发者平台):这类系统的主要“用户”是开发者。它们提供了一套工具、服务和 API,旨在加速其他团队的应用开发和交付。
- Integration Hub (集成中心):一个专注于连接不同(通常是异构的)系统和应用的平台。它负责处理数据转换、协议适配和流程编排。
- Dev Portal (开发者门户):通常是 API 平台的一部分,它是开发者发现、学习、测试和管理 API 的“店面”。
总结:架构是一个“选择”的游戏
这张思维导图清晰地表明:软件架构不是一个单一的选项,而是一个广阔的“光谱”。
更重要的是,这些类别并不是相互排斥的。一个现代系统几乎总是这些模式的“混合体”:
你可能拥有一个基于 Microservices(按组合)的 Developer Platform(按目的),服务之间通过 REST(按连接)和 Pub/Sub(按事件)进行通信,并采用 Data Mesh(按数据)的理念来管理数据。
作为开发者和架构师,我们的工作就是理解这张“藏宝图”,根据业务需求、团队规模、性能目标和可维护性等原则,从工具箱中选择并组合出最适合当前问题的解决方案。