LLM 参数高效微调(PEFT)最常用的 5 种技术全解析:LoRA、LoRA-FA、VeRA、Delta-LoRA、LoRA+
为什么需要参数高效微调
在大模型时代,对 LLM 进行全参微调(Full Fine-tuning)往往不切实际。以百亿级参数模型为例,完整微调需要:
- 数百 GB 显存/内存
- 极高成本的算力集群
- 长时间训练周期
为了解决这些问题,业界提出了 PEFT(Parameter-Efficient Fine-Tuning) ——通过只训练模型的一小部分参数,实现接近全参微调的效果。
PEFT 的核心思想通常围绕:
为模型中的权重矩阵寻找一种“低秩表示”,从而利用极少的额外参数实现有效学习。
这篇文章将用清晰的结构介绍最主流的 5 种 PEFT 技术,帮助读者从系统层面理解它们的思路与差异。
背景:为什么低秩近似对 LLM 微调如此重要?
每一层 Transformer 都包含大量矩阵乘法,例如:
- Attention 的 Q/K/V 投影矩阵
- FFN 层的线性变换
这些权重矩阵规模巨大(例如 4096×4096),直接训练成本过高。
而低秩分解(Low-Rank Decomposition)告诉我们:
大型矩阵中有效信息往往能通过低维子空间表示。
因此,许多 PEFT 方法的核心做法是:
- 不直接改动原始权重矩阵 W
- 而是添加轻量级的 低秩矩阵 A、B
- 或设计更小维度的可训练结构
Top 5 LLM 微调技术详解
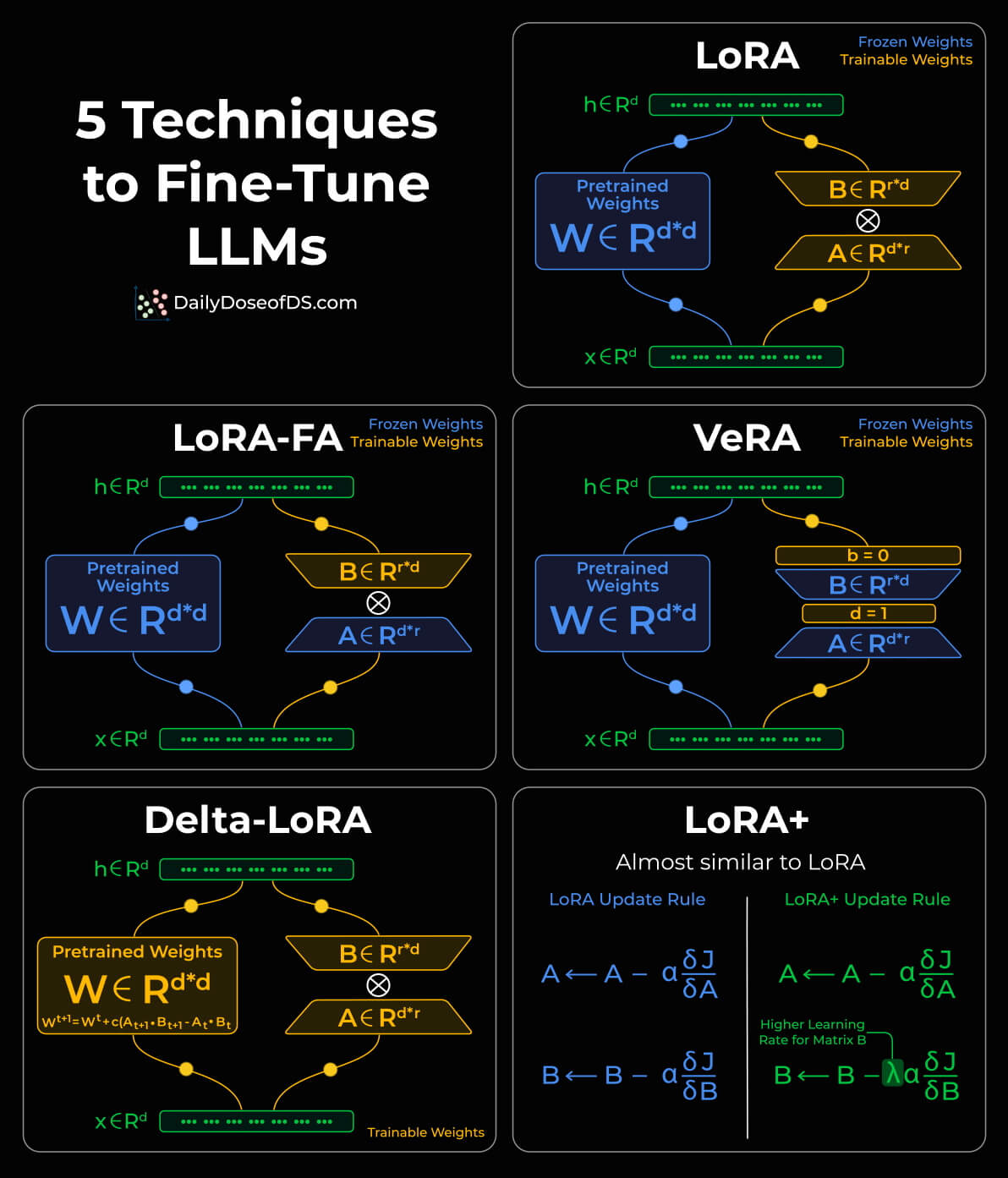
1)LoRA:最经典、最广泛采用的 PEFT 技术
核心思想:
在原始权重矩阵 W 旁边引入两个小型矩阵 A(降维) 与 B(升维)。
训练时:
- W 保持冻结
- 只训练 A 和 B
- 更新形式:
ΔW = B × A
特点:
- 额外参数极少(秩通常为 4~64)
- 对显存友好
- 性能与全参微调接近
LoRA 目前已成为最标准的 PEFT 技术,几乎所有框架(如 HuggingFace PEFT、LLaMA-Factory)都默认支持。
2)LoRA-FA:降低激活内存占用
LoRA 的训练过程需要:
- 保留 A 和 B 的梯度
- 保留中间激活值
这会消耗相当多的显存。
LoRA-FA 的改进方式:
- 冻结矩阵 A
- 仅训练矩阵 B
这样可以大幅减少:
- 激活缓存
- 反向传播的中间梯度
优点:
- 更节省显存(适合 13B / 70B 模型微调)
- 参数规模更小
应用场景:
- 显存紧张
- 需要更高 batch size
3)VeRA:进一步减少参数 & 提高共享度
LoRA 中的 A 和 B 是每一层都不同的。
VeRA 提出的改进:
- A 和 B 不再是可训练矩阵
- 而是 固定的随机矩阵
- 并且 所有层共享同一组 A 与 B
模型不再学习 A 和 B,而是学习:
- 针对每一层的标量向量 b(入射缩放)与 d(输出缩放)
这让参数量进一步缩小到极限。
特点:
- 极低参数量
- 微调速度快
- 适合多任务场景(共享结构)
4)Delta-LoRA:将增量信息直接合并到权重中
传统 LoRA:
- 最终的 ΔW 来自 B×A
Delta-LoRA 的思路:
- 观察训练过程中低秩更新的变化
- 将 前后两个时间步 A×B 的差值(delta)累积到原始 W 中
形式类似:
W ← W + [(B×A)_{t} − (B×A)_{t−1}]特点:
- W 被逐步更新,但无需传统全参训练
- 仍保持低秩结构的优势
适用场景:
- 需要让权重本体存储更多增量信息
- 对推理阶段不希望依赖 LoRA 插件
5)LoRA+:优化学习率策略的简单升级版
在 LoRA 中:
- A 和 B 共享相同的学习率
研究发现:
- 提高 B 的学习率
- 保持 A 的学习率不变
能让:
- 训练更稳定
- 收敛更快
- 性能更高
本质是一种 更优的学习率调度策略,无需额外结构。
优点:
- 实现简单
- 没有额外显存开销
- 效果稳定提升
技术对比总结
| 技术 | 是否训练 A | 是否训练 B | 是否训练 W | 参数量 | 显存占用 | 场景 |
|---|---|---|---|---|---|---|
| LoRA | ✔️ | ✔️ | ❌ | 小 | 中 | 主流微调方式 |
| LoRA-FA | ❌ | ✔️ | ❌ | 更小 | 更低 | 显存紧张 |
| VeRA | ❌ (Random) | ❌ (Random) | ❌ | 极低 | 极低 | 多任务/极限压缩 |
| Delta-LoRA | ✔️ | ✔️ | ✔️ (Incremental) | 中 | 中 | 希望更新到主权重 |
| LoRA+ | ✔️ | ✔️ (Higher LR) | ❌ | 小 | 中 | 更快收敛 |
结语
随着模型规模持续增长,PEFT 将长期成为 LLM 微调的核心方法。LoRA 及其衍生技术各有特点:
- LoRA 是标准方案
- LoRA-FA 专注显存优化
- VeRA 追求极低参数共享
- Delta-LoRA 为权重更新提供新路径
- LoRA+ 利用学习率策略提升效果
理解这些方法的差异,有助于在工程实践中做出最适合的选择,如:
- 推理效率与部署限制
- 目标任务规模
- 可用算力